Context Engineering: The Invisible Skill That Determines Whether Your AI Agents Actually Work
The one skill that separates production-grade AI agents from expensive hallucinations.
Your AI agent is hallucinating. It's confidently telling customers the wrong order status, making up code that doesn't exist, and giving medical advice that would get a human stripped of their license.
Whose fault is it?
Chances are, it's not the model. It's not the prompt. It's the context.
Context engineering—the invisible discipline that nobody talks about—is the #1 reason AI agents fail in production. And if you're still thinking in terms of "prompt engineering" alone, you're already behind the curve.
What Is Context Engineering, Really?
Let's get precise.
Context engineering is the art and science of filling the context window with the right information, at the right time, in the right format. It's the discipline that sits between a language model's raw capability and the reliable behavior your users actually need.
Think of it like this: LLMs are like a new kind of operating system, where the model acts as the CPU and its context window functions as the RAM—the working memory the model uses to think.
"LLMs are like a new kind of operating system. The model is the CPU, the context window is the RAM."
— Andrej Karpathy
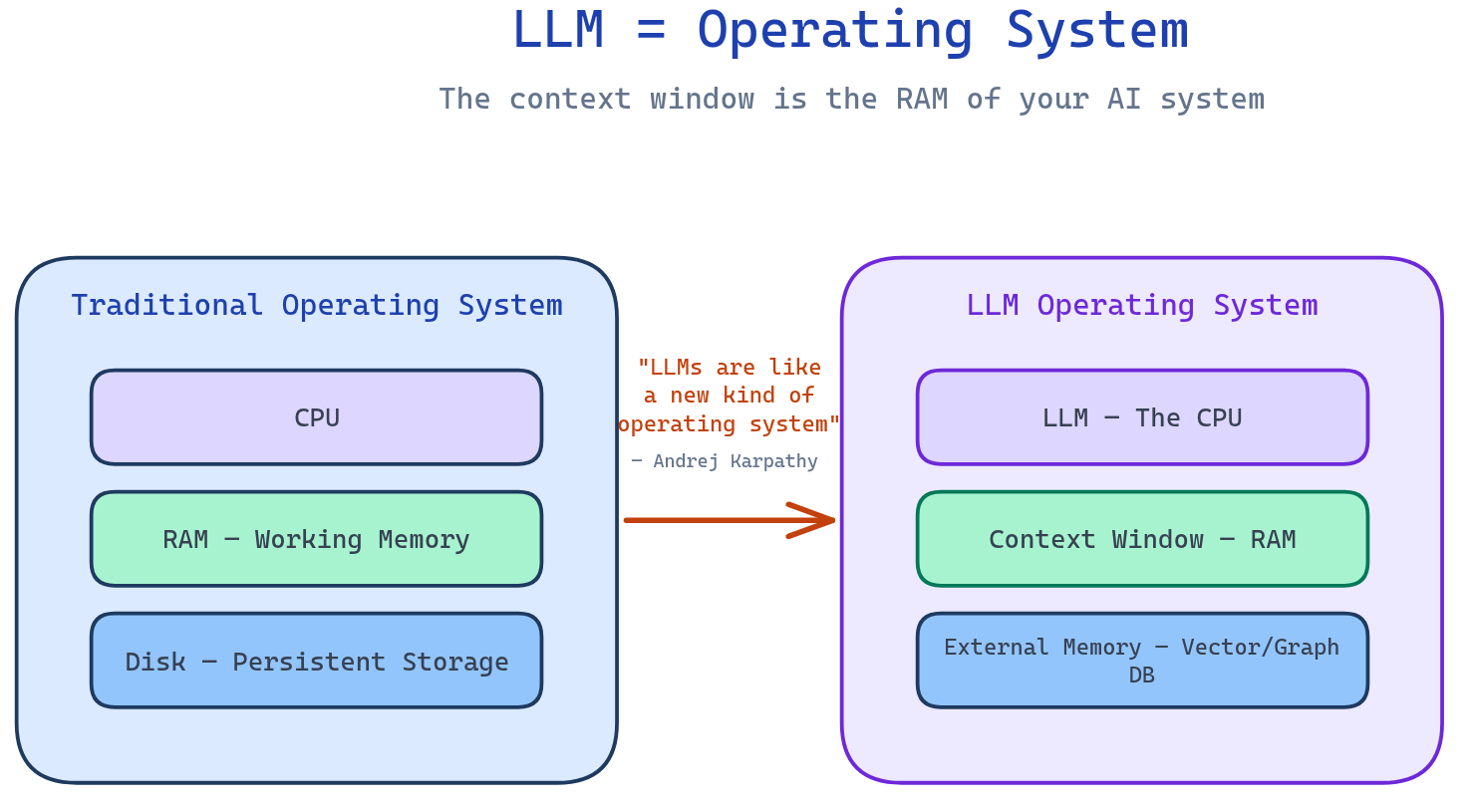
Just as an operating system manages what fits into RAM, context engineering curates what occupies the model's working memory at each step. Every token in that window is competing for the model's attention.
The key insight? Context engineering is not the same as prompt engineering.
Prompt engineering focuses on crafting individual instructions. Context engineering is the discipline that governs everything that enters the context window: instructions, conversation history, retrieved knowledge, tool definitions, user preferences, and the examples that teach the model what "good" looks like.
With multi-turn agents, long-horizon tasks, and tools that generate reams of intermediate data, prompt engineering alone simply doesn't cut it anymore.
The Anatomy of Context
To engineer context effectively, you first need to understand what you're actually working with.
The context sent to an LLM isn't a static string—it's dynamically assembled from multiple sources, each with distinct characteristics:
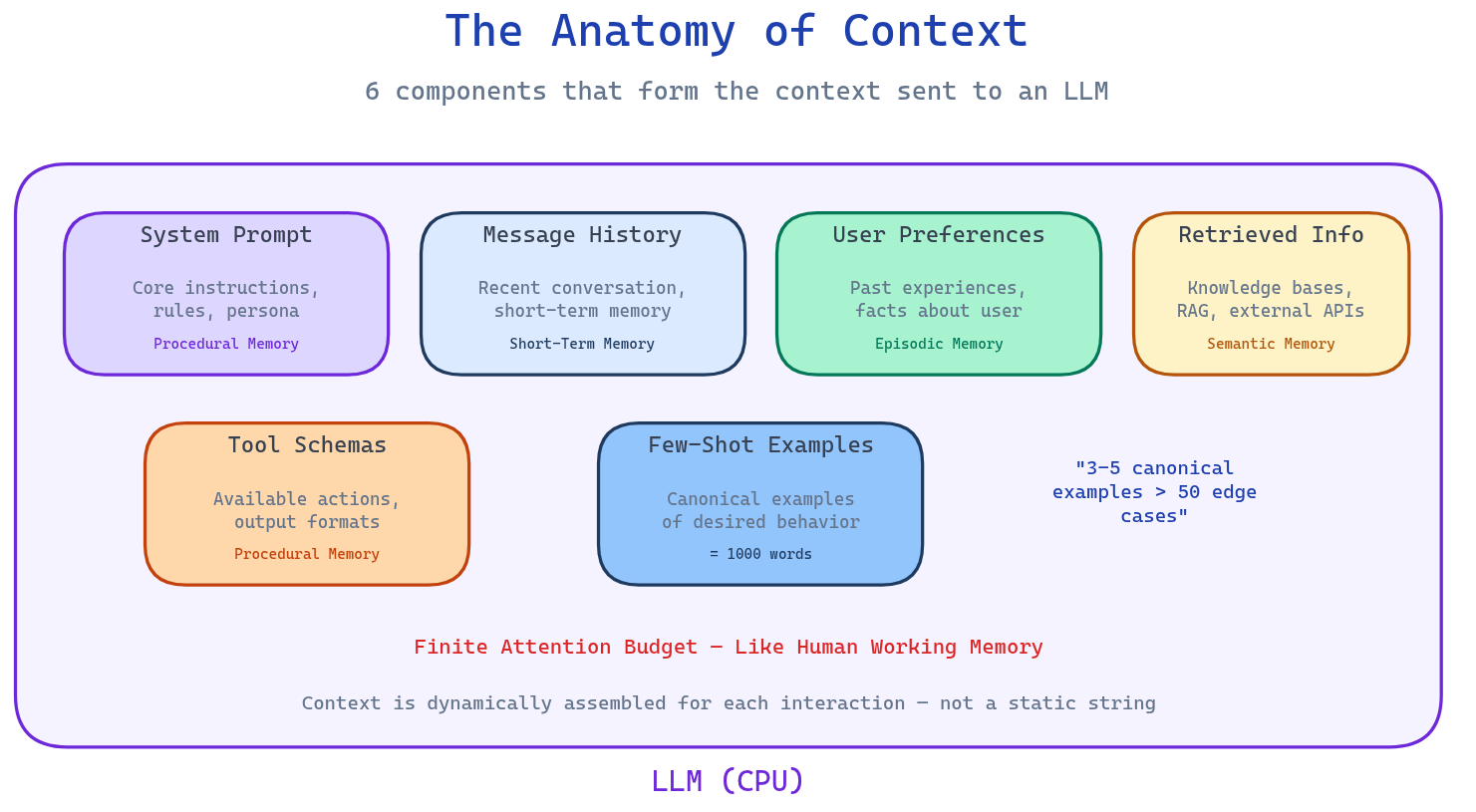
1. System Prompt (Procedural Memory)
The core instructions, rules, and persona that define how the agent should behave. This is your north star for agent identity—but it only works if it's clear, direct, and at the right altitude. Too vague, and the model improvises. Too brittle, and it breaks at the first edge case.
2. Message History (Short-Term Memory)
The recent back-and-forth of the conversation, including tool calls, observations, and internal monologue. This is where most agents start losing the thread. As history grows, the signal-to-noise ratio drops.
3. User Preferences (Episodic Memory)
Facts about the user, stored in a vector or graph database. "This user prefers concise responses." "She always asks about pricing first." This memory enables personalization that feels natural rather than robotic.
4. Retrieved Information (Semantic Memory)
Knowledge pulled from internal databases, company documents, or external APIs in real-time. This is the core of RAG (Retrieval-Augmented Generation)—but retrieval without relevance filtering is just expensive noise.
5. Tool Schemas (Procedural Memory)
Definitions of what actions the agent can take, including parameters and output formats. This is where most agents fail spectacularly. Overlapping tool descriptions cause paralysis. Unclear parameters cause wrong tool selection. If a human can't tell which tool to use, the LLM definitely can't.
6. Few-Shot Examples
Canonical demonstrations of desired behavior. Here's the thing: 3-5 well-chosen examples outperform 50 edge cases. The model learns patterns, not exhaustive rule lists.
Each component draws from a different type of memory (procedural, short-term, episodic, semantic), and they're all competing for the same finite resource: the model's attention budget.
The 4 Problems Destroying Your Agents
Before we get to solutions, let's be honest about what's actually breaking your systems.
1. Context Window Overflow
Every token you add to the context window costs money and adds latency. But that's the shallow problem. The deep problem is that self-attention—the mechanism powering LLMs—has quadratic computational overhead. More context isn't linearly harder; it's exponentially harder.
When your agent's context window fills up, two things happen: cost spikes, and quality degrades.
2. Context Decay — The Lost-in-the-Middle Problem
Here's the research that should keep you up at night: model correctness drops significantly after 32,000 tokens—long before the advertised 2 million token limits.
Why? LLMs are trained on shorter sequences where positional patterns are more consistent. As context grows, models naturally lose focus on information embedded in the middle—the "lost-in-the-middle" problem. Information at the beginning and end of the context gets weighted more heavily, while critical details buried in the middle get ignored or misremembered.
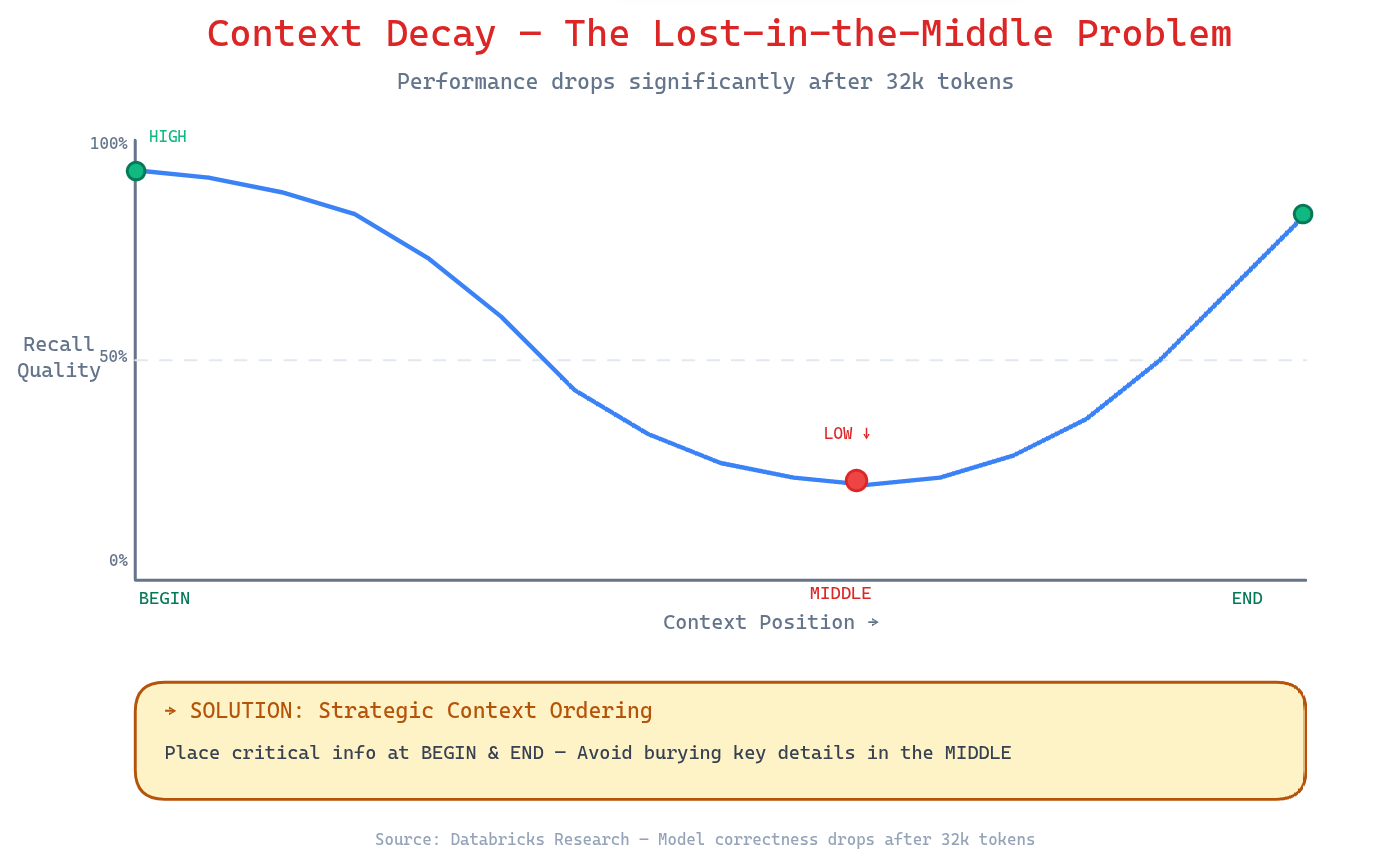
The symptoms? Confused responses, contradictory outputs, and hallucinations that fill perceived gaps with plausible-sounding fiction.
3. Context Drift
Over time, conflicting facts accumulate in the context. The memory says "budget is $500." The retrieved document says "budget is $1,000." The model, unable to resolve the contradiction, either guesses or generates confident nonsense.
Without a mechanism to prune or resolve outdated facts, your agent's knowledge base becomes unreliable exactly when you need it most.
4. Tool Confusion
The Gorilla benchmark found something brutal: nearly all models perform worse when given more than one tool. Not just slightly worse—measurably worse.
When tools have overlapping functionality or unclear descriptions, the model second-guesses itself, picks the wrong tool, or worse—uses two tools incorrectly in the same turn.
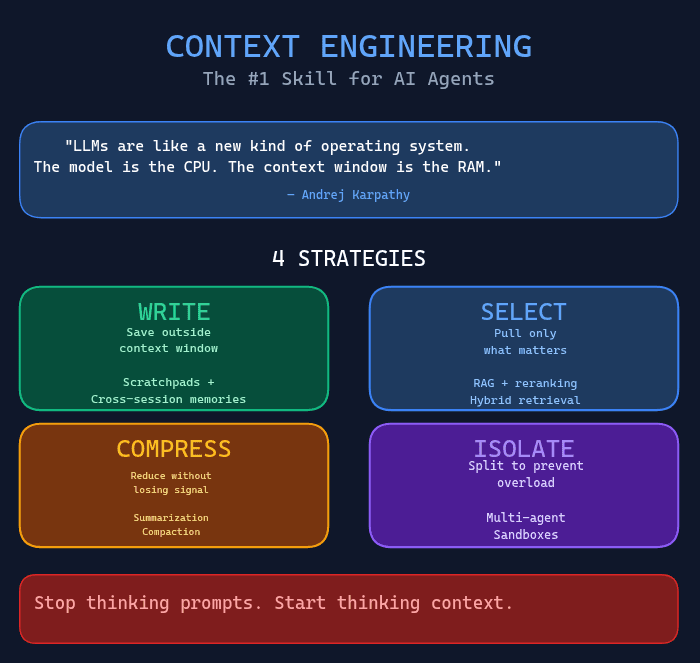
The 4 Strategies of Context Engineering
Here's the framework that actually works. Four levers to keep context under control:
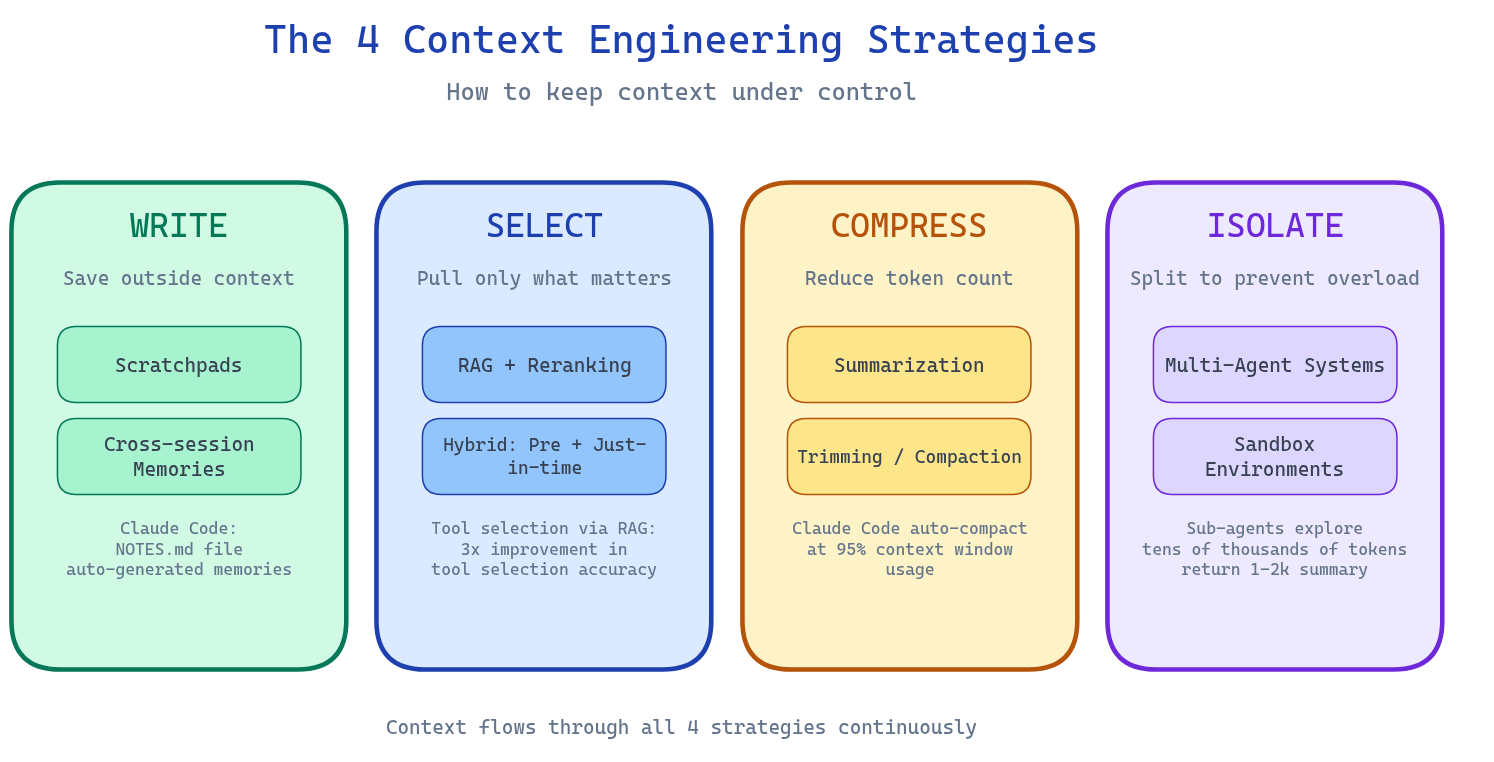
WRITE — Save Outside the Context Window
Don't keep everything in RAM. Write intermediate results, state, and notes to persistent storage outside the context window.
Scratchpads: Agents take notes during task execution—temporary storage that's available for retrieval but doesn't consume context. Claude Code does this with auto-generated NOTES.md files that track progress across complex tasks.
Cross-session Memories: Some information should persist across conversations entirely. User preferences, project context, accumulated learnings. Tools like Mem0, ChatGPT Memory, or custom vector stores handle this.
The principle: The context window is precious. Only keep what's actively needed right now in the window. Everything else goes to disk.
SELECT — Pull Only What Matters
RAG (Retrieval-Augmented Generation) is table stakes—but naive RAG dumps everything into context. That's not retrieval; that's a fire hose.
RAG with reranking: Don't retrieve everything that might be relevant. Retrieve the most relevant facts, then rerank to surface the highest-signal results. Token efficiency is a feature, not a bug.
Hybrid retrieval: Combine pre-inference retrieval (data loaded before the model runs) with just-in-time retrieval (data loaded during reasoning). Claude Code uses CLAUDE.md files upfront, but relies on glob and grep to explore files only when needed.
Tool selection via RAG: Recent research shows that applying semantic search to tool descriptions—retrieving only the most relevant tools for a given task—improves tool selection accuracy by 3x.
YAML over JSON: If you're sending structured data in context, use YAML. It's 66% more token-efficient than JSON, and LLMs parse it just as well.
COMPRESS — Reduce Without Losing Signal
When context approaches its limits, compress rather than truncate.
Summarization: Claude Code automatically triggers "auto-compact" at 95% context window usage. It summarizes the conversation history, preserving critical decisions and discarding redundant tool outputs.
The art of compaction: What do you keep vs. discard? Overly aggressive compaction loses subtle but critical context. The key is maximizing recall first, then iterating to improve precision. Start broad, cut carefully.
Trimming: Not everything needs to be summarized. Older messages, redundant tool results, and intermediate outputs that served their purpose can be hard-deleted. Tool result clearing is the lightest touch—and often the highest ROI.
ISOLATE — Split to Prevent Overload
When a problem is too complex for one context window, split it across multiple agents.
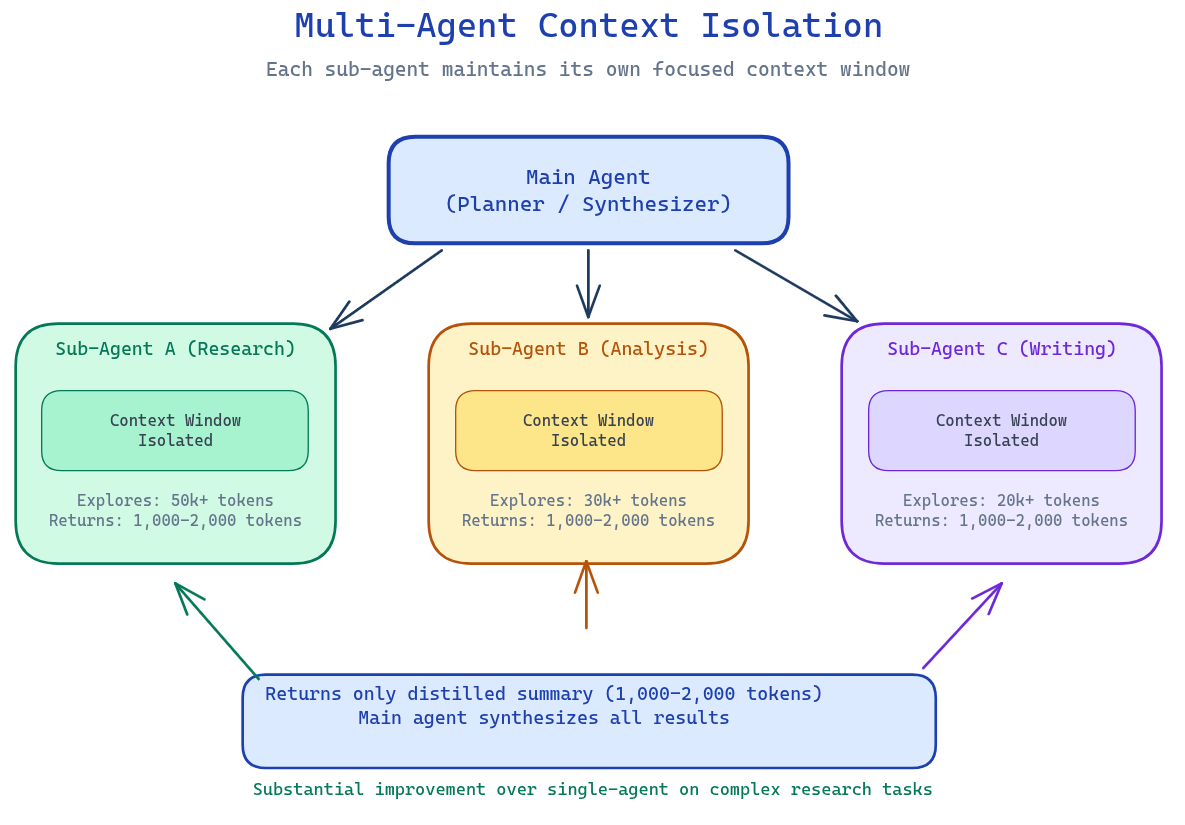
Multi-agent architectures: Anthropic's multi-agent research system uses sub-agents that explore different aspects of a question in parallel, each with their own context window. They return only distilled 1,000-2,000 token summaries. The main agent synthesizes.
The trade-off: Multi-agent systems use significantly more tokens (up to 15x more than a simple chat, by Anthropic's measurements). The investment pays off when the task complexity justifies it—which is most real-world production workloads.
Sandbox environments: HuggingFace's deep researcher runs agent code in sandboxes where state persists without flooding the LLM's context. Heavy objects—images, intermediate files, large datasets—live in the sandbox and get referenced, not embedded.
Techniques for Long-Running Agents
When your agent needs to work for hours, not seconds, context management becomes existential.
Compaction
Before you hit the context limit, summarize. Claude Code's approach: the model reviews the message history, distills architectural decisions, unresolved bugs, and implementation details, then discards redundant tool outputs. The new context starts with this summary plus the five most recently accessed files.
This is not memory loss—it's intelligent compression. The agent retains continuity without being buried in its own trail.
Structured Note-Taking
The agent writes its own notes—persisted outside the context window, readable when needed. This is agentic memory.
Claude playing Pokémon demonstrates this at scale: it maintains precise tallies across thousands of game steps, tracks objectives, and builds strategic notes across multi-hour sessions. After each context compaction, it reads its own notes and continues where it left off.
The pattern: agents that write notes complete long-horizon tasks that agents without memory cannot even attempt.
Sub-Agent Architectures
For complex research, analysis, or multi-domain problems, one agent trying to hold everything in context is a losing battle.
Main agent: planner and synthesizer. Sub-agents: specialized workers with isolated contexts exploring narrow domains. Each sub-agent can use tens of thousands of tokens exploring its domain, then returns only a distilled summary.
This isn't just about context management—it's about specialization. A research agent and a writing agent have different context requirements, different tool sets, and different optimization targets. Isolation enables focus.
The Tools That Make This Work
You don't need to build everything from scratch. The ecosystem has matured:
Frameworks: LangGraph, LangChain—orchestration with context management built in
Memory systems: Mem0, LangMem, ChatGPT Memory—persistent memory without the plumbing
Vector/Graph databases: Qdrant, Neo4j, PostgreSQL + pgvector—storage for semantic and episodic memory
Observability: LangSmith, Opi, Langfuse, MLflow—see what's actually in your context at runtime
Sandboxes: E2B, CodeAgent—isolate heavy computation from the LLM context
Context engineering isn't about using more tools. It's about using the right tools in the right sequence.
Best Practices That Actually Matter
If you remember nothing else from this article, remember this:
The smallest set of high-signal tokens that maximize the likelihood of your desired outcome.
Everything else is implementation detail. Here's how to get there:
Structure prompts into distinct sections with clear delineation
Outils sans overlap fonctionnel—minimal viable set
3-5 canonical examples > 50 edge cases
YAML over JSON for structured data
Compaction before 95% context usage
Note-taking persisted outside the context window
Hybrid retrieval: pre-inference + just-in-time
Position critical instructions at the beginning, recent/relevant data at the end
The Point
Context engineering is not a feature. It's the discipline that determines whether your AI system works or fails.
"Context engineering is effectively the #1 job of engineers building AI agents."
— Cognition
Garbage in, garbage out has never been more relevant. The context you provide—the tokens you select, order, compress, and isolate—is the difference between an agent that reliably does your job and one that confidently fails in expensive ways.
Stop thinking about prompts. Start thinking about context.
Sources
Enjoyed this article? Share it!